
Las tecnologías de Big Data y Cloud han evolucionado en paralelo, sin embargo, ¿pueden convivir estas tecnologías?, ¿es posible aprovechar las ventajas del Cloud para las plataformas de Big Data? Son preguntas que a menudo nos formulamos y que sorprende la facilidad que la respuesta supone. En éste artículo, abordaré algunos de los retos y sobre todo las oportunidades que hay para enriquecer las plataformas de Big Data en Cloud. Me centraré en Apache Kafka gobernado desde la Plataforma Confluent, una plataforma que ofrece una interesante solución al análisis de datos vía streaming en tiempo real.

Un poco de historia
Confluent
Apache Kafka es un proyecto de intermediación de mensajes de código abierto publicado en el año 2011 y desarrollado originalmente por la empresa LinkedIn en código Scala. Tres años más tarde, en 2014, varios ingenieros del proyecto fundaron la empresa Confluent, una compañía americana de Big Data. Con el fin de facilitar a las empresas el fácil acceso a datos en tiempo real, se han enfocado en crear una plataforma para el análisis y procesamiento de eventos vía streaming a partir de Kafka.
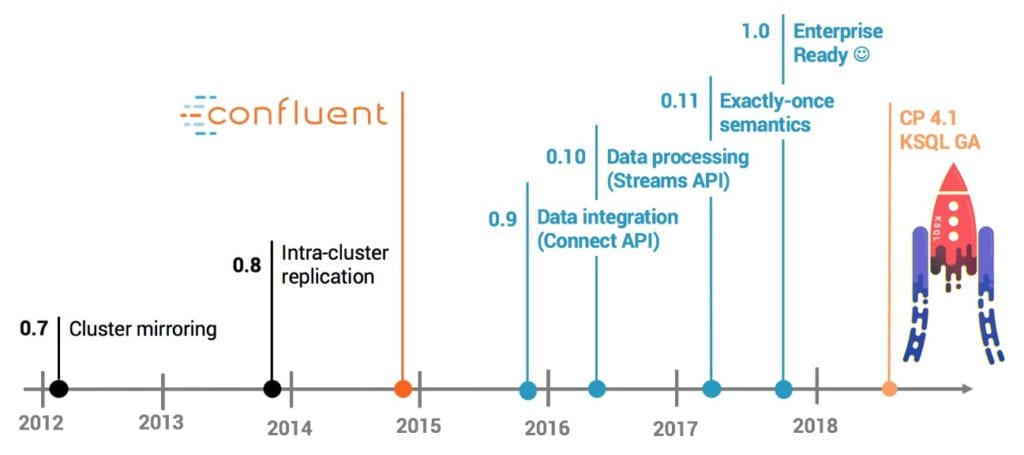
Confluent es un producto relativamente reciente. Pero incluso antes, nos encontrábamos en pleno auge y estandarización de plataformas Cloud.
Las “CLOUD WARS”
Las plataformas Cloud es algo que utilizamos todos, aunque muy a menudo incluso no seamos conscientes de ello. Sin retroceder demasiado en el tiempo y nombrando a los competidores más grandes, en 2006 Amazon lanzó su famosa AWS (Amazon Web Services). Cuatro años más tarde, le siguió Microsoft con su plataforma Azure en 2010 y finalmente Google en 2013 con GCP (Google Cloud Platform).
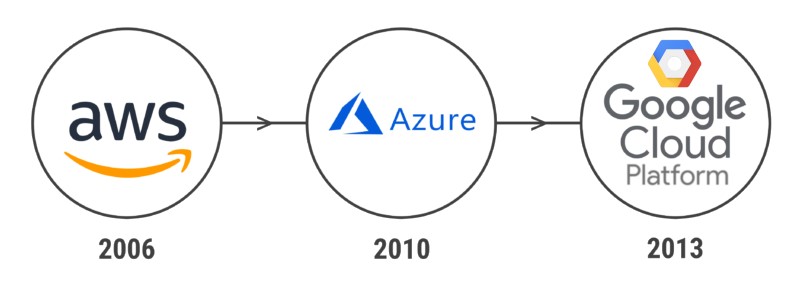
No es el objetivo de éste artículo el hacer una comparativa entre las plataformas y las ventajas de los servicios de cada una que suponen a los negocios. Se trata de poner en contexto que éstas grandes compañías multinacionales están continuamente mejorando sus servicios y plataformas, provocando que el nivel de competitividad en esta “Cloud Wars” sea continuamente un escenario cambiante y emocionante, al mismo tiempo que intentan abarcar el máximo mercado posible.
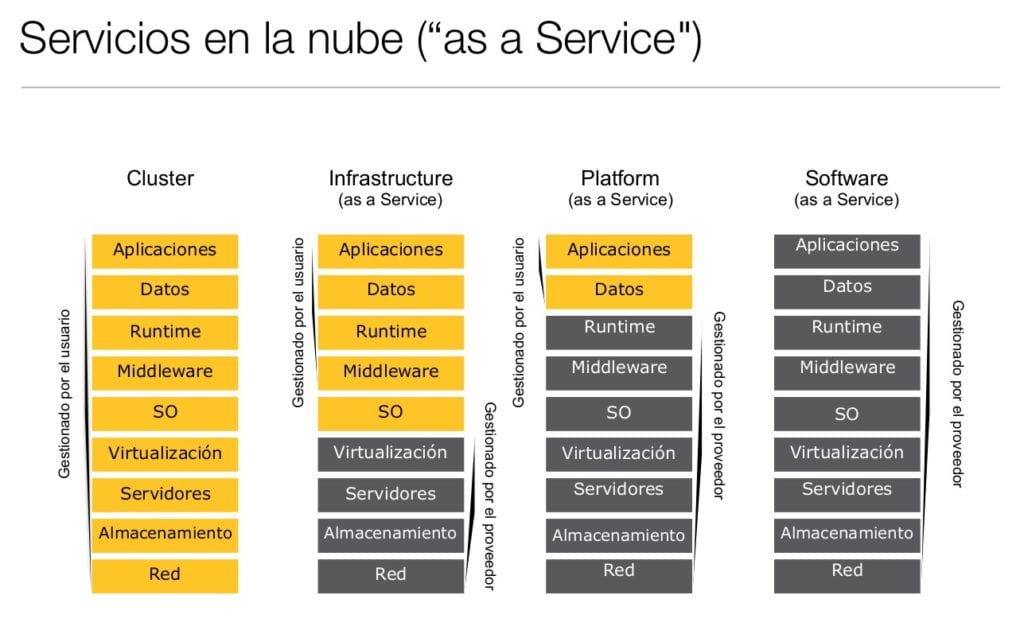
Primero, para entender cómo pueden ser útiles los servicios Cloud en la Arquitectura, se debe identificar los tipos de servicios: IaaS (Infrastructure as a Service), PaaS (Platform as a Service) y SaaS (Software as a Service).
De una forma simple lo ejemplifico suponiendo que la aplicación es un coche:

- IaaS: Eres dueño de tu coche y puedes conducirlo.
- PaaS: Puedes alquilar un coche, no eres dueño de él, pero puedes conducirlo.
- SaaS: Puedes coger un taxi, ni lo conduces ni eres dueño del mismo, pero al final te presta un servicio de trasladarte de un sitio a otro.
Me centraré, en el concepto de IaaS. La definición de IaaS abarca aspectos como el espacio en servidores virtuales, conexiones de red, ancho de banda, direcciones IP y balanceadores de carga. Físicamente, el repertorio de recursos de hardware disponibles procede de multitud de servidores y redes, generalmente distribuidos entre numerosos centros de datos, de cuyo mantenimiento se encarga el proveedor del servicio cloud. El cliente, por su parte, obtiene acceso a los componentes virtualizados para construir con ellos su propia plataforma informática.
Abstrayendo (y mucho!) esta idea, se puede decir en este caso que sea On Premise (el «hierro» instalado en los CPD) o sea On Cloud, para nosotros:

Teniendo en cuenta lo anterior, ¿es posible tener una arquitectura de Confluent en Cloud y On premise? La respuesta rápida es sí. Sin embargo, habrá que tener muy en cuenta los pros y contras de esta situación, no solo en el ahorro a nivel económico, sino también a nivel de eficiencia de los clústeres de Confluent (latencia de red, seguridad, accesos, GDPR…).
Como alternativa sí se quiere construir la infraestructura, existe la opción en el otro extremo. En 2017 Confluent presentó su Confluent Cloud, como un Apache Kafka as a Service (SaaS). A partir de abril de 2019, ofrece el servicio utilizando por debajo las plataformas de AWS. Como novedad hace unos días, incluyeron el servicio de Google Cloud, con una ligera mejora en los precios.

¿“Clústeres” de Confluent?
Sí se dispone de tecnologías Cloud y Big Data, ¿por qué no combinarlas? De esta forma se puede aprovechar todo el potencial de ambas.
Un ejemplo claro es el de disponer de un segundo clúster para un caso de Disaster Recovery: DC-1 (on Premise) y DC-2 (on Cloud):
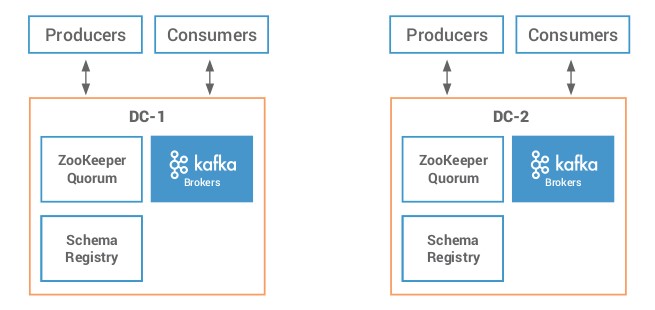
Otro ejemplo a considerarse es la migración de un clúster On Premise al Cloud. La ventaja es que se abaratan los costes de mantenimiento que normalmente pueda conllevar los servidores físicos y demás componentes que los envuelven.
En este escenario el objetivo es el de mantener toda la información sincronizada en ambos clústeres. Adicional a las propias configuraciones de los componentes, es necesario contar con:
- Replicación de datos entre clústeres (contenido de los topics).
- Preservar la marca de tiempo en los mensajes.
- Prevención de la repetición cíclica de topics.
- Resetteo de los consumer offsets.
- Gestión centralizada de esquemas para el Schema Registry.
¿Cómo migrar los contenidos de Kafka a Confluent On Cloud?
Confluent es una Plataforma basada en Kafka, entonces ¿es posible tener los datos de un clúster de Kafka en otro clúster de Confluent? La respuesta es ¡sí!, en función del objetivo al que se destina el clúster. La parte más compleja para este escenario es configurar el sistema de la forma más óptima posible, para que, en caso de caída del clúster la posibilidad de pérdida del dato sea lo menor posible.
Para decantar por uno, se debe tener en cuenta qué uso se va a dar a cada clúster y las ventajas e inconvenientes de su montaje:
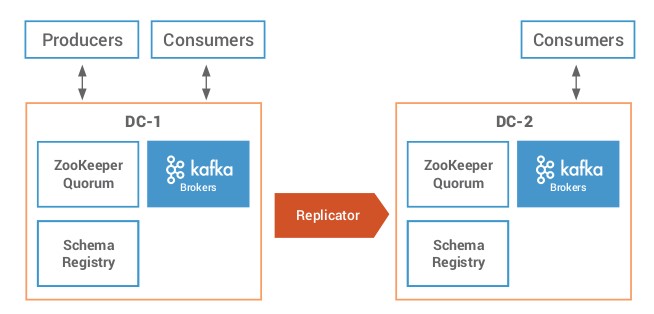
Activo – Pasivo
Este es el escenario más sencillo. En caso de desastre, el cambio a un nuevo clúster es prácticamente transparente, ya que se dispone de la misma información en un clúster que en el que se ha caído. En caso de querer hacer una migración de un clúster On Premise a un clúster On Cloud, bastará con replicar los contenidos y dar de baja el antiguo clúster.
Activo – Activo
Éste escenario es más complejo, ya que una sincronización en ambos sentidos no siempre es sencilla. En el caso de la replicación de la información del Schema Registry, se deberá definir el que actuará como Schema Primario en un clúster y el que actuará como Schema Secundario. De ésta forma sí cae el Primario, el Secundario pasa a ser el Primario, hasta que se recupere el clúster caído.
Otro riesgo a considerar es la replicación cíclica de mensajes. Esto se pueden abordar de forma sencilla con el uso de Replicator, no con el Mirror Maker de Kafka.
También es importante gestionar el detalle de los consumer offsets de los topics y su marca de tiempo, de forma que tanto si se ataca a un clúster como a otro, siempre se obtiene la misma información de ambos.
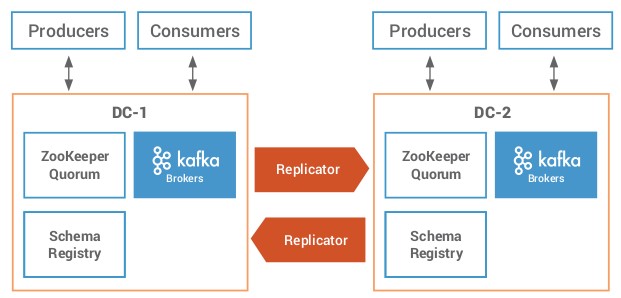
Confluent Replicator
Confluent provee de una herramienta dentro de la gran variedad de Conectores llamada Replicator, mucho más avanzada que el Mirror-Maker original de Kafka. Dentro de la documentación de Confluent, se puede consultar una interesante comparativa entre ambos.
En función de las necesidades, depende el uso del Replicator de Confluent o el Mirror Maker de Kafka. Para ello se tiene que tomar en cuenta sí se cuenta con la licencia para el componente.
Una de las ventajas de contar con Confluent, es la posibilidad de controlar y monitorizar el Replicator en el Control-Center, configurando interceptors dentro del fichero de configuración del Connect. Esto permite que se pueda supervisar la sincronización correcta entre ambos clústeres.
Adicionalmente, es imporante considerar que el Replicator siempre se activa en el clúster de destino, de forma que eres dueño y supervisor de la copia de dicho Confluent.
¿Hay algunas opciones más?
Desde luego hay otras opciones. Seguro has oído hablar de Docker y la gestión de contenedores con Kubernetes, ¿y de Mesosphere DC/OS? ¿No? Quizás deberías echar un vistazo al catálogo de aplicaciones de Mesosphere.
DC / OS Confluent Kafka es un servicio automatizado que facilita la implementación y administración de Confluent Kafka en Mesosphere DC / OS, eliminando casi toda la complejidad tradicionalmente asociada con la administración de un clúster Kafka. Proporciona acceso directo a través de la API de Confluent Kafka para que los productores y consumidores existentes puedan interoperar. Además, se pueden instalar múltiples clústeres de Confluent Kafka en DC / OS y administrarse de manera independiente, ofreciendo Confluent Kafka como un servicio administrado. Con ello se obtienen las siguientes ventajas:
- Fácil instalación
- Gestión de múltiples clústeres de Kafka Confluent
- Escalado elástico de los brokers
- Replicación y apagado controlado para alta disponibilidad
- Monitorización de clústeres y brokers de Kafka Confluent
Si bien es cierto que no todos los productos de Confluent están dentro del catálogo de aplicaciones de Mesosphere DC/OS (como el KSQL) y que no siempre disponen de la última versión de Confluent (actualmente es la 5.2 de Confluent), puede ser una interesante vía para gestionar y administrar los clústeres según las necesidades. Es posible combinarlo con otros productos del catálogo como HDFS, Spark, Redis, Microservicios, etc. Con ello es posible disponer de una arquitectura Big Data en un tiempo récord, y des echándola cuando ya no sea necesario su uso.
Enlaces de interés
- Announcing Confluent Cloud: Apache Kafka as a Service
- Disaster Recovery for Multi-Datacenter Apache Kafka Deployments
- Confluent Multi Data Center Replication:
- Blog de Mesosphere (Confluent):
- Building a Confluent Platform Data Pipeline on DC/OS:
Sobre mí:
Desde que finalicé mis estudios en Ingeniería Informática, tengo como objetivo formarme continuamente en nuevas tecnologías que me aporten cada vez más experiencia y constituyan nuevos retos. Como Big Data Specialist en PUE administro plataformas de Big Data, trabajando con diferentes máquinas, infraestructuras y tecnologías para manejar grandes volúmenes de datos. Ayudo a que los usuarios obtengan valor de sus datos dentro del gran abanico de posibilidades que el mundo de Big Data ofrece.



Sobre PUE
Como líder de Big Data, Cloud, Microservicios, NoSQL y DevOps en España, el objetivo de PUE es, siempre, ofrecer a sus clientes las mejores soluciones con las últimas tecnologías: soluciones innovadoras propuestas por un equipo técnico certificado, expertos en Administración, Analista de Datos, Científico de Datos y Desarrollo.
Para más información sobre los servicios de PUE:
Servicios y soluciones con PUE
Formación y certificación oficial
Contacta para saber más en:
![]() consulting@pue.es
consulting@pue.es ![]() Solicitud de información para la implantación de proyectos
Solicitud de información para la implantación de proyectos




