Cloud
El éxito en la migración al cloud computing.
Modernización de la infraestructura
Escalable y rentable
La reducción de costes es posible gracias a la optimización de los recursos, definiendo los tipos almacenamiento de acuerdo al tipo de dato y costes e incrementando los recursos de acuerdo a las necesidades del negocio.
Reducimos el impacto de la migración al Cloud para que puedas obtener todos los beneficios de modernizar la infraestructura:
Computación de alto rendimiento
Automatización y optimización de recursos
El Cloud permite gestionar la infraestructura como un servicio, reduciendo costes y tareas rutinarias de operaciones.
En PUE optamos por la implantación de arquitecturas full stack con CI/CD aplicado a la automatización de procesos en Infraestructura y Desarrollo, así como por arquitecturas de microservicios basados en contenedores que permiten la optimización del consumo de recursos y la escalabilidad automática de los servicios en base a la demanda de carga de trabajo.
Analítica de Datos
Decisiones basadas en datos
Diseñamos y creamos Data Lakes y Data Warehouses para ser capaces de analizar los datos en tiempo real mediante herramientas cloud native. Para ello, no sólo optimizamos el uso de herramientas en las cuales somos expertos, como el caso de BigQuery, si no que las integramos en la plataforma existente para que los sistemas puedan convivir y ser capaces de sacar el máximo rendimiento. Esto nos permite enfocar la analítica de datos no solo en tiempo real, si no también siendo capaz de tener una ingesta más flexible, escalable, gobernada y segura, facilitando así no sólo el análisis y la creación de informes, si no también la predicción mediante el aprendizaje automático integrado.
Machine Learning & AI
Conocimiento de los datos
Utilizamos los datos para implementar modelos de ML & AI con la suite de servicios de Google Cloud (Vertex AI), para ayudar a las empresas a optimizar su negocio, conocer mejor a sus clientes, prevenir riegos y ahorrar tiempo con modelos disruptivos y entrenados.
La reducción de costes es posible gracias a la optimización de los recursos, definiendo los tipos almacenamiento de acuerdo al tipo de dato y costes e incrementando los recursos de acuerdo a las necesidades del negocio.
Reducimos el impacto de la migración al Cloud para que puedas obtener todos los beneficios de modernizar la infraestructura:
El Cloud permite gestionar la infraestructura como un servicio, reduciendo costes y tareas rutinarias de operaciones.
En PUE optamos por la implantación de arquitecturas full stack con CI/CD aplicado a la automatización de procesos en Infraestructura y Desarrollo, así como por arquitecturas de microservicios basados en contenedores que permiten la optimización del consumo de recursos y la escalabilidad automática de los servicios en base a la demanda de carga de trabajo.
Diseñamos y creamos Data Lakes y Data Warehouses para ser capaces de analizar los datos en tiempo real mediante herramientas cloud native. Para ello, no sólo optimizamos el uso de herramientas en las cuales somos expertos, como el caso de BigQuery, si no que las integramos en la plataforma existente para que los sistemas puedan convivir y ser capaces de sacar el máximo rendimiento. Esto nos permite enfocar la analítica de datos no solo en tiempo real, si no también siendo capaz de tener una ingesta más flexible, escalable, gobernada y segura, facilitando así no sólo el análisis y la creación de informes, si no también la predicción mediante el aprendizaje automático integrado.
Utilizamos los datos para implementar modelos de ML & AI con la suite de servicios de Google Cloud (Vertex AI), para ayudar a las empresas a optimizar su negocio, conocer mejor a sus clientes, prevenir riegos y ahorrar tiempo con modelos disruptivos y entrenados.
Propuesta de infraestructura

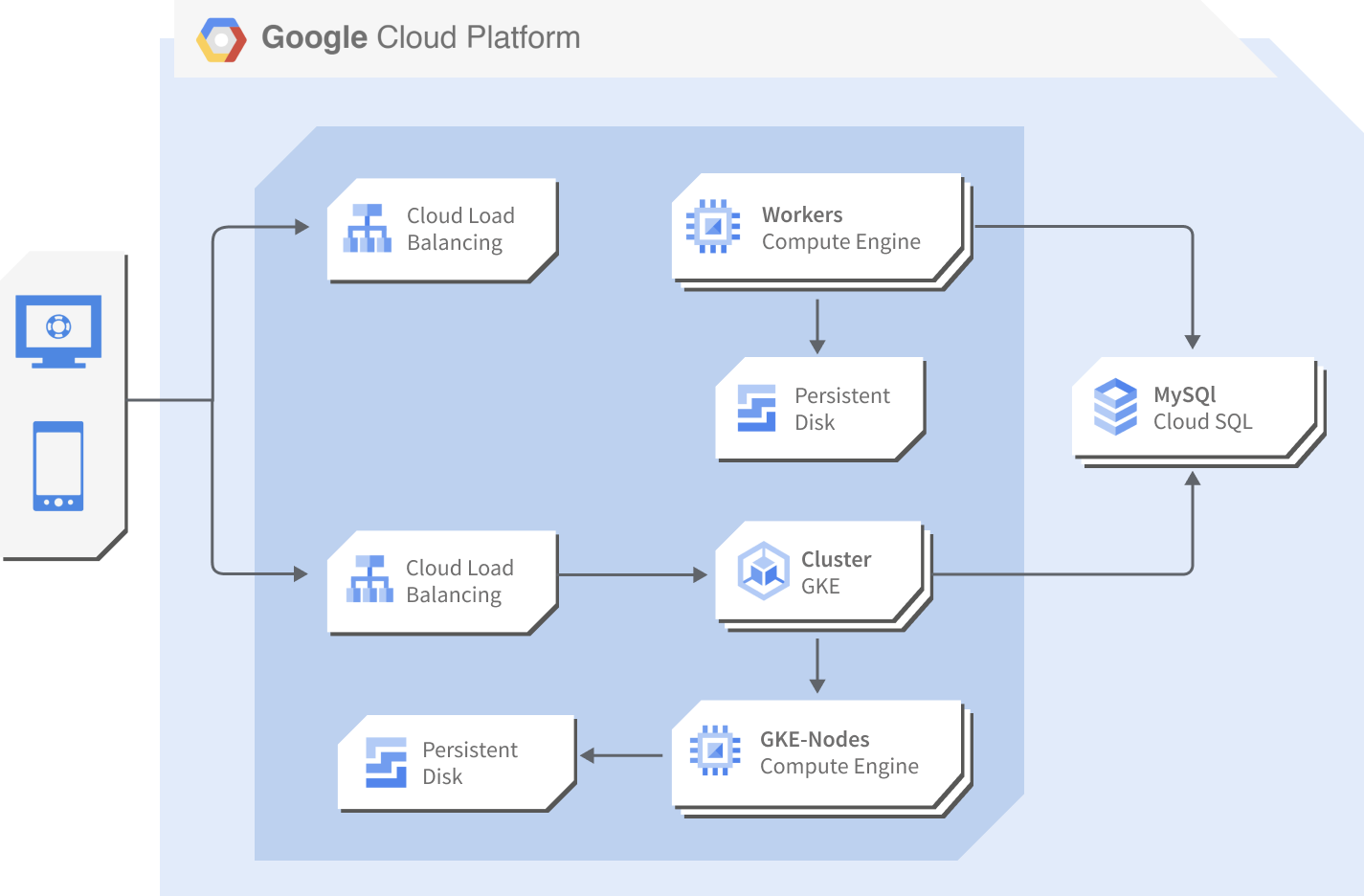
Caso de Uso:
Containers en GKE & Hosts en Compute Engine

Proyecto de análisis de datos sobre infraestructura
de microservicios en Google Cloud

Objetivos

- Evolucionar una plataforma de B2C a B2B.
- Disponer de dos clusters, uno productivo y otro pre-productivo con capacidades de contingencia en un entorno de Cloud Pública basado en Google Cloud.
- Desarrollar las funcionalidades del proyecto.
- Soporte a la solución para cubrir el ciclo de vida completo de Big Data.
Entorno Google Cloud
La solución plantea el uso de la infraestructura de proyecto de Google, donde principalmente destacan los componentes:
- Compute Engine
- Google Kubernetes Engine
- Cloud Storage
- Cloud SQL
- VPC Network
Tipos de instancias
Para la creación de dos entornos diferenciados pre y pro totalmente intercambiables, se proponen dos entornos independientes e idénticos en infraestructura que permiten cumplir funciones de contingencia. Cada entorno consta de los siguientes componentes:
- 3 Nodos Máster
- 6 Nodos Worker

La distribución de servicios y los tipos de instancias recomendados son:
|
Servicios |
Master Nodes |
Worker Nodes |
|---|---|---|
|
MapReduce |
N1-highmem-8 |
N1-highmem-8 |
|
HBase |
N1-highmem-8 |
N1-highmem-8 |
|
Todos los |
N1-highmem-8 |
N1-highmem-8 |
Google Kubernetes Engine
Para los procesos de cliente, se usa el servicio de microservicios GKE con las siguientes características:
- 2 clusters: preproducción y producción.
- 2 plantillas de instancias, una para cada cluster.
- Tipos de nodos corriendo en los clusters: n1-standard-1.
Arquitectura de servicios

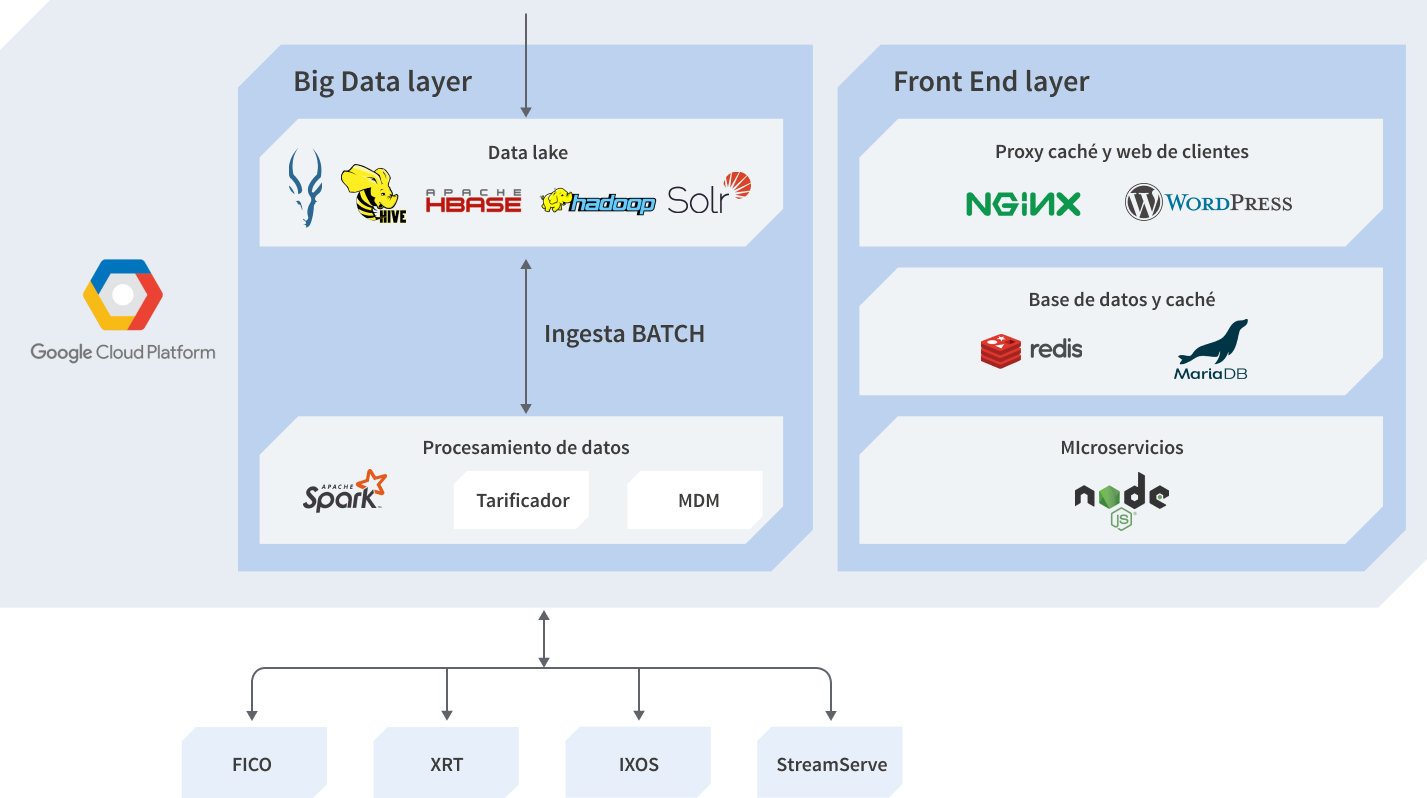
Fase de análisis de datos
Capa de almacenamiento
|
Tipo |
Componente |
Descripción |
|---|---|---|
|
Principal |
HDFS |
Sistema de almacenamiento distribuido, core para el resto de sistemas y procesamiento. |
|
Principal |
HBAse |
Base de datos columnar para el acceso de baja latencia y escalable a datos no aleatorios. |
|
Opcional |
KUDU |
Base de datos de rendimiento intermedio entre HBase y HDFS. |
|
Principal |
Parquet |
Formato de almacenamiento columnar sobre HBase y con posibilidad de compresión. |
|
Principal |
Avro |
Contenedor de información en HDFS que permite la compresión y almacenar en metadatos el esquema de la información disponible. |

Fase de entrada de datos
|
Elemento |
Elementos |
Descripción |
|---|---|---|
|
Syslog TCP |
Syslog TCP Source en Flume y Kafka |
Se usará flume para la recepción de información con una fuente de escucha TCP. |
|
Ficheros en directorios locales/red |
Spool Source en Flume y Kafka |
Se usará Flume para el pooling de nueva información en directorios parametrizados. |
|
Bases de datos relacionales |
Sqoop |
Sqoop se encarga de la ingesta tanto completa como incremental de fuentes estructuradas SQL. |
|
Servicios Web |
HTTP Source en Flume y JSON Handler y Kafka |
Se usará un conector a servicios web con el manejo de contenido en JSON. |
Fase de procesado de datos
|
Requisito |
Componente |
Descripción |
|---|---|---|
|
Procesamiento Batch |
Spark |
Procesamiento de datasets completos in-memory de forma altamente efectiva. |
|
Procesamiento Real-Time |
Spark Streaming |
Procesamiento micro-batch en ventanas de tiempo. |
|
Filtrado, Transformación, Agrupación y Enriquecimiento |
Spark Streaming, Spark SQL HBase |
Spark Streaming en conjunto con Spark SQL (facilita la codificación de procesos) para las opciones de filtrado. HBase para acceder con baja latencia a las bases de datos y poder explotar las funciones de transformación y enriquecimiento. |
|
Procesos Analytics y Machine Learning |
MLlib, GraphX |
Procesos Spark que usan las librerías de Machine Learning. |
|
Indexación de texto, agregación y series temporales |
SolR |
SolR permite la indexación de documentos para su posterior búsqueda ágil incluso en entornos visuales (integración con Hue para su explotación). |
|
Toma de Decisiones Near Real-Time |
Spark |
Diseño de motor de reglas para la toma de decisión y actuación en micro-batch de baja latencia. |
|
Compresión de Datos |
Avro y Parquet |
Permiten la lectura y escritura junto con un procesamiento nativo de datos comprimidos. |
Fase de explotación de datos
|
Requisito |
Módulo |
Descripción |
|---|---|---|
|
Entorno Visual |
HUE |
Hue es el entorno unificado para la explotación de datos, permite conectar con todos los componentes del cluster de forma visual y realizar los procesos necesarios desde un entorno visual e intuitivo. |
|
Consultas SQL-Like |
Hive/Impala |
Hive es el motor habitual de consultas. Se incluye Impala como motor de baja latencia para mejorar los tiempos de respuesta de quieres. |
|
Integración con Terceros |
ODBC/ WebServices/ Sqoop |
Se puede realizar la conexión a través de conexiones JDBC/ODBC para la lectura de datos con Hive, o bien a través de WebServices como con HBase y el volcado de datos en bases de datos externas a través de Sqoop. |